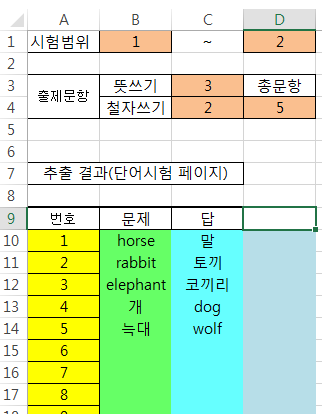
[VBA] 검색되는 단어, 검색되지 않는 단어 찾기
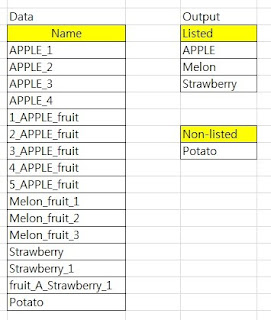
지식인에서 들어온 질문. 리스트상의 단어가 데이터상의 단어를 포함한 긴 단어에 있을 경우 해당하는 모든 중복되는 데이터에 대해 Listed 밑에 리스상의 단어로 하나만 표기하면 됩니다. 가령 APPLE 이 리스트 단어이면 DATA상에 APPLE_1/APPPL_2가 있으면 그냥 APPLE 만 표기하도록 매크로를 작성해주세요. List에 없는 단어 중 Name에 있으면 Non-listed에 표시해주세요 여기서는 안보이지만, Apple, Melon, Strawberry, Pear 등으로 이루어진 List목록이 따로 있다 Potato는 List목록에는 없는데 Name에는 있기때문에 Non-listed에 표시된다. 사실 앞의 문제는 해결이 쉽다. .Find 메서드를 이용하면 된다. 시트에서 Ctrl-F 를 누른 것과 같은 기능을 한다. c = Worksheets(1).Range("a1:a500").Find(2, lookin:=xlValues) 위는 a1:a500에서 2라는 값을 찾아서 셀을 반환한다. 즉, 여기서 C 는 Range 변수로 정의되어야한다. 그런데 두번째 문제가 좀 어려웠다. List에 있는 각 단어를 가지고 Name에 있는 셀을 다 찾은 다음, Name에 있는 단어를 하나씩 이용해서 List를 뒤져야하나? 그러면 시간이 오래 걸릴 것 같아서 기각이다. 마침내 방법을 생각해 냈는데, 배열변수를 이용하는 것이다! 배열변수의 크기를 Name의 단어 갯수만큼 설정하고 Find 및 Findnext를 이용해서 List에 있는 단어를 계속 찾고,, 찾을 때마다 해당 셀의 위치(행번호)를 배열변수의 위치에다 매칭시킨다 예를 들어, Name에 100개의 단어가 A1셀부터 A100셀까지 들어있으면 arr라는 배열변수를 arr(1)부터 arr(100)까지 설정한다. (초기값은 0이다) 이제 List에 있는 첫번째 단어를 ...