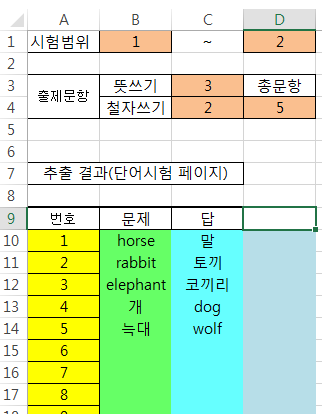
LOOKUP함수. 문자중 일부를 문자열에서 찾는 방법

이런 식으로 과일에 대한 가격이 매겨져 있습니다. 이제 다른 곳에 견적서를 작성한다고 하면, 품명에 "사과" "배' 등으로 기록하면 그 품목에 대한 가격을 구하는 것은 VLOOKUP함수로 쉽게 할 수 있다. 하지만, 지금처럼 해당 품명이 들어있긴하지만 다른 문자들과 섞여 들어가 있어 VLOOKUP함수를 그대로 적용할수는 없는 상황이 있습니다. 이런때, 다른 문자들이 섞여 있긴 하지만 해당 품목을 문자속에서 찾아서 해당 품목의 가격을 알고 싶다면 어떻게 할까요? 큰형님 이 멋진 답을 주셨습니다. =LOOKUP(1,1/FIND($E$2:$E$7,A2),$F$2:$F$7) 수식 해석 함수 LOOKUP(1 1을 다음 배열에서 찾는다 1/ 뒤의 배열에 있는 숫자각각으로 1을 나눈다 lookup함수의 두번째인수, 1을 찾을 배열 FIND($E$2:$E$7,A2) A2안에 사과~수박의 문자배열중 있는 글자가 있는지 찾는다 lookup함수의 두번째인수, 1을 찾을 배열 $F$2:$F$7 위에서 찾은 배열의 문자가 해당 배열에서 차지하는 위치와 같은 위치에 있는 문자를 F2:F7 배열에서 찾는다 lookup함수의 세번째 인수, 1이 위치한 곳과 같은 위치를 찾을 곳 여기서 find함수의 쓰임에 주목할 필요가 있습니다. FIND(find_text, within_text, [start_num]) 즉, find(찾을문자,찾을장소,[시작위치])로 써야하는 함수입니다. 그런데 여기서는 find(범위,문자)로 썼습니다. 보통의 사용법과는 반대입니다. FIND($E$2:$E$7,A2) 을 말로 풀이하면 "E2:E7 안에 있는 문자들 중 A2셀의 문자와 같은게 있으면 그 위치가 어딘지 각자 배열로 표시해봐"가 될것입니다 FIND($E$2:$E$7,A2)을 수식계산에서 돌려보면